Principes d'urbanisation pour un système d'information
ou comment tirer partie des standards d'Internet dans les entreprises.
Publié le 26/12/2008 - Mis à jour le 30/12/2008 par Jean-Paul Figer
- Contexte
- Modularité et encapsulation
- Sécurité
- Unicité de la localisation d'une information
- Unicité de la localisation du pilotage des activités
- Garantie de la cohérence fonctionnelle
- Asynchronisme des pilotes
- Non-exclusivité des données
- Services sans états
- Référentiels passifs
- Annexe 1 : le style d'architecture REST
- Annexe 2 : [Optimistic locking]
- Annexe 3 : Les alertes, les affaires et les indicateurs métier
Ce guide présente des principes d'urbanisation fondés sur un style d'architecture REST. Quelques éléments du style REST sont fournis en annexe 1. J'ai aussi écrit un article détaillé sur REST ici.
Ces principes restent valables quel que soit le style d'architecture pour l'urbanisation de tout système d'information complexe.
Cet article a été publié sous le numéro H6000 dans la rubrique Architecture des systèmes des Techniques de l'Ingénieur.
Contexte
Les Systèmes d'Information de la plupart des grandes entreprises se sont construits graduellement au cours des vingt dernières années sous forme d'applications indépendantes où les informations sont dupliquées.
Ceci se traduit par les cinq fameuses ruptures :
- Rupture des applications : les mises à jour des données ne sont pas répercutées entre applications ;
- Rupture des identifiants : une même information est accessible via de multiples identifiants. Par exemple un même article est identifié différemment par l'application de gestion des commande et par l'application de gestion des stocks, ce qui rend les répercutions des mises à jour difficiles voire impossibles ;
- Rupture de la chaîne informatique : les échanges entre applications ne sont pas industrialisés, ce qui entraîne des défauts de traitement et des erreurs dans la répercutions des mises à jour ;
- Rupture temporelle : les délais de répercussion des mises à jour d'information entre applications sont longs (plusieurs semaines voire plusieurs mois) ;
- Rupture géographique : les données sont dispersées dans les applications implantées dans les différentes entités géographiques (pays par exemple).
Il en résulte des incohérences, des saisies multiples et un service peu satisfaisant pour les utilisateurs et pour l'entreprise.
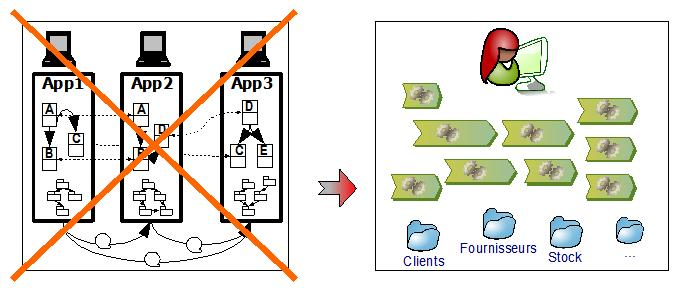
Pour résoudre ces ruptures, il est souvent décidé de restructurer le système d'information autour de référentiels de données transverses accessibles et utilisés par l'ensemble des traitements informatiques comme indiqué sur la figure ci-dessus. Ce choix, qui pourrait paraître purement technique, a en fait de nombreuses implications au niveau métier et fonctionnel. Ce choix impose le respect d'un corpus de principes de conception, sous peine soit de réintroduire les ruptures soit de rendre ingérable la complexité du système d'information.
L'objet de ce document est d'expliciter les principaux principes de ce corpus.
Ce choix a aussi des implications importantes au niveau de la conception applicative et de l'exploitation informatique. Pour simplifier l'expression des principes, on se place délibérément dans un style d'architecture informatique REST. Pour des détails sur le style REST, voir en annexe 1 et l'article sur ce site)
Cet article emploie les concepts issues du modèle MDA -Model Driven Architecture- de l'OMG -Object Management Group-. Ce modèle définit 3 vues principales :
- CIM -Computation Independent Model- ou modèle métier ;
- PIM -Platform Independent Model- qui est SOA REST ;
- PSM -Platform Specific Model- qui dans le cas de REST est une transformation triviale.
Les principales caractéristiques du style d'architecture REST qui sont utilisées dans ce document sont :
- La notion de « Ressource » désignée par un identificateur unique global URI ;
- Le protocole sans état HTTP qui permet d'obtenir une représentation de la ressource souvent appelée information dans ce document ;
- Des liens hypermédias pour donner accès au contenu des informations (données et métadonnées) et pour spécifier les transitions entre états des traitements ;
- Les types MIME comme text/xml, text/html, image/jpeg, application/pdf, video/mpeg pour la représentation des ressources.
Il n'y a pas de raison qu'un nouveau protocole ne soit pas mieux adapté à REST que le protocole HTTP. Il faut cependant noter que les protocoles plus anciens ne fournissent pas suffisamment de métadonnées ou nécessitent trop d'interactions avec le réseau.
Modularité et encapsulation

Principe 1 : Modularité et encapsulation
Le Système d'Information est partitionné en sous-ensembles fortement cohérents et faiblement couplés : les Services Fonctionnels (SF).
Ce principe est un principe lié au système d'information et n'est pas un principe métier. Il découle de 2 raisons principales :
- Complexité de réalisation : il est illusoire de vouloir construire un SI de la taille d'un SI d'entreprise, en particulier d'une grande entreprise, en un seul morceau et il est nécessaire de le découper en sous-ensembles plus faciles à appréhender ;
- Facilité de maintenance : dans un SI de la taille d'un SI d'entreprise, il est indispensable de pouvoir modifier une partie du SI tout en contrôlant les impacts, en particulier la localisation de ces impacts, de manière à ne pas avoir à reconstruire et requalifier l'ensemble du SI à chaque évolution.
Pour cela, on segmente le SI suivant des critères fonctionnels par identification de sous-ensembles fortement cohérents et faiblement couplés :
- fortement cohérents : les données et les traitements à l'intérieur d'un sous-ensemble sont conceptuellement proches ;
- faiblement couplés : une évolution d'un sous-ensemble impacte au minimum les autres sous-ensembles.
Ces sous-ensembles sont appelés Services Fonctionnels (SF). Il s'agit d'une structuration purement fonctionnelle, les aspects applicatifs ou techniques n'entrent pas en ligne de compte à ce niveau.
Les Services Fonctionnels sont de 2 types :
- Services Fonctionnels Silos (SFS): ils fournissent à l'ensemble du SI les services liés à leurs données - c'est leur dimension silo de données ou référentiels
- Services Fonctionnels Pilotes (SFP) : ils fournissent la réalisation d'un ensemble de traitements.
Afin de maximiser la facilité de maintenance du système d'information, il est essentiel de limiter et de contrôler les impacts d'une modification locale de l'implémentation d'un SF - par exemple lors de la correction d'un bogue ou d'une évolution non fonctionnelle pour améliorer les performances ou lors d'un changement de plate-forme technologique. Dans ce cadre, les SF doivent masquer les détails internes de leur implémentation, en particulier la structuration interne du stockage de leurs données. Les SF ne donnent donc accès à leurs données que via des offres de services précisément décrites et publiées.
Ceci est résumé dans la règle suivante :
Règle 1a
Les SF Silo encapsulent leurs données et communiquent via des offres de services décrites et publiées.
Sécurité
"...La faiblesse du modèle habituel de défense d'un périmètre, généralement utilisé par les entreprises, est devenue douloureusement évidente."
Rapport PITAC de février 2005 remis au Président des Etats-Unis : Cyber Security, a crisis of Prioritization
La défense d'un périmètre habituellement employée par les entreprises consiste à protéger l'intérieur d'un système informatique contre un attaquant venu de l'extérieur. Les inconvénients sont nombreux :
- Dès que la barrière est franchie (vulnérabilité logicielle, erreur opérateur,...), l'attaquant peut compromettre l'ensemble des systèmes sans guère plus d'efforts que pour en compromettre un ;
- Il n'y a pas de protection contre un attaquant de l'intérieur ;
- La distinction intérieur/extérieur disparaît avec la prolifération des équipements connectés, le Wi-Fi, la complexité des réseaux.
Il convient donc de remplacer le modèle "défense d'un périmètre" par un modèle plus réaliste, la suspicion réciproque. On remplace la dialectique :
- Question : Qui dois-je craindre ?
- Réponse : j'interdis !
par
- Question : En qui puis-je avoir confiance ?
- Réponse : j'authentifie et j'autorise.
Cette distinction permet de découpler les contraintes de la sécurité du SI de celles de l'infrastructure technique. La sécurité repose sur la sécurisation des échanges deux à deux, pas sur la sécurité d'une zone ou d'un réseau. Chaque service authentifie les demandes et autorise ou n'autorise pas chaque transaction. Si nécessaire le canal de communication (HTTPS) ou tout ou partie de la transaction peut être chiffré pour garantir l'intégrité et la confidentialité des informations.

Principe 2: Sécurité
La sécurité est fondée sur une infrastructure de confiance : authentification réciproque des acteurs avant d'autoriser les échanges.
Chaque SF gère ses propres règles d'autorisations.
Une règle de sécurité stricte stipule que les flux de contrôle sont toujours à l'initiative du destinataire (mode Pull). Chaque SF garde donc un contrôle total sur ses données.
La raison de ce principe est l'augmentation des risques causée par la concentration de l'ensemble des données dans un ensemble de référentiels. Le piratage d'un des référentiels aura potentiellement des impacts sur l'ensemble des traitements de l'entreprise. Il devient donc essentiel d'isoler de manière stricte les éléments auxquels le monde extérieur a accès et qui sont potentiellement la cible des pirates informatiques. Seul le SF peut modifier ses données à son initiative.
Afin de se prémunir, autant que possible, de l'imagination des pirates informatiques qui pourraient trouver des failles dans les mécanismes de sécurité, il est nécessaire de pouvoir déconnecter 'physiquement' un SF en cas de suspicion d'intrusion. Il s'agit alors d'un mode dégradé, par exemple les commandes des internautes seront traitées plus lentement. La durée de cette déconnection dépend des analyses à effectuer et potentiellement de la durée de la mise en place de nouveaux mécanismes, ce qui peut prendre plusieurs jours. Ceci justifie la règle suivante :
Règle 2a :
Chaque SF doit pouvoir fonctionner temporairement de manière autonome.
Cette règle améliore la sécurité et la robustesse des systèmes en limitant la propagation des incidents.
Unicité de la localisation d'une information

Principe 3 : Unicité de la localisation d'une information
Une information est gérée en un point unique du système d'information.
Il peut exister des copies des informations pour assurer l'archivage, certains recoupements en temps différé ou d'autres raisons. Ces copies ne sont pas accessibles directement par les référentiels ou les traitements du système d'information.
L'objectif de ce principe est de garantir le maintien de l'intégrité et de la fraîcheur des informations dans le Système d'Information.
Il s'agit ici de bien distinguer le concept de donnée du concept d'information : une même donnée peut correspondre à des informations différentes. Par exemple, l'adresse courante d'un client et l'adresse indiquée sur une facture peuvent être la même donnée mais pas nécessairement la même information : si le client a coché la case 'livraison à mon adresse habituelle' alors il s'agit de la même information, sinon il s'agit de la même donnée mais de deux informations différentes - cette distinction est importante en particulier si le client vient de faire une demande de changement d'adresse par courrier postal et passe une commande par internet avant que le changement d'adresse ne soit effectif. Le principe ci-dessus s'applique aux informations et pas aux données : les données doivent être dupliquées quand il s'agit d'informations différentes.
La première partie du principe est le fondement de l'approche permettant d'éviter les ruptures et l'incohérence des informations.
La deuxième partie du principe reconnaît le caractère particulier des copies du système d'information :
- Les traitements de ces copies ne participent pas de manière synchrone à l'activité courante de l'entreprise ;
- Ces traitements ont besoin d'une structuration spécifique des données pour permettre les recoupements, et
- ces traitements n'ont pas besoin d'informations fraîches (au contraire, ils utilisent en général des historiques, souvent des informations de millésimes précédents).
Une conséquence importante de ce principe est la suivante :
Règle 3a
Les modèles de données des référentiels sont disjoints deux à deux.
Cette conséquence implique le concept d'identifiant unique informatique ou URI dans le modèle REST. Dans la plupart des cas, cet identifiant unique sera un URL fourni par un service référentiel, c'est à dire le lien vers la ressource qui fournit l'information. Lorsque cette information n'existe pas dans le système ou n'est pas un document numérique, il est possible d'utiliser un URN comme par exemple pour un livre urn:isbn:3-540-43081-4
Règle 3b
Chaque information du Système Informatique possède un URI, qui vérifie les 4 propriétés :
- non-signifiance : un identifiant n'a pas de signification.
- non-modification : un identifiant ne peut pas être modifié.
- non-réutilisation : un identifiant ne peut pas être réutilisé même après destruction de la donnée associée.
- non-destruction : un identifiant ne peut pas être détruit même s'il n'est plus utilisé.
Cet URI qui permet de gérer des relations entre les différentes informations du système d'information. Un référentiel contient donc ses données et des URI permettant de pointer vers les informations des autres référentiels.
La propriété de non-signifiance est une conséquence du principe d'unicité de la localisation d'une information (principe 3) : si l'identifiant était signifiant alors il y aurait duplication d'information et donc fort risque d'incohérence. Prenons par exemple le numéro de sécurité sociale d'une personne. Ce numéro ne peut pas servir comme identifiant informatique car on pourrait en déduire la date de naissance de la personne ; si jamais il s'avérait que la date donnée lors de l'attribution du numéro était fausse alors il faudrait corriger la date de naissance dans le référentiel des personnes - mais alors tous les autres applicatifs qui utilisent le numéro de sécurité sociale pour en déduire l'âge donneraient des résultats incohérents. Pour éviter ces incohérences, on pourrait imaginer de changer l'identifiant pour y mettre la bonne date de naissance mais il faudrait alors diffuser cette modification dans tous les référentiels qui font référence à cette personne. Il faudrait donc soit gérer dynamiquement la liste des référentiels qui font référence à cette personne, soit avertir tous les référentiels. Dans les deux cas, il s'agit de mécanismes complexes et difficiles à rendre résistants à tous les types de pannes possibles. Il est clair qu'il est beaucoup plus simple et robuste d'utiliser des identifiants non signifiants et d'invoquer le référentiel des personnes pour connaître la date de naissance.
La propriété de non-modification permet de garantir la pérennité des identifiants. En effet, comme nous l'avons vu, un URI peut être stocké dans d'autres référentiels. Si on modifiait cet identifiant, alors les références contenues dans les autres référentiels deviendraient invalides et les relations entre ces informations ne pourraient plus être faites. Il faudrait donc avertir les autres référentiels de la modification pour qu'ils la prennent en compte. Comme ci-dessus, on pourrait diffuser la modification à l'ensemble des référentiels mais cela générerait un gigantesque trafic de messages de modification dans un système de la taille d'un système d'information d'entreprise. On pourrait aussi ne diffuser qu'aux référentiels qui font référence à cet URI, ce qui imposerait de gérer une liste inverse des références ; autrement dit un référentiel devrait savoir à tout moment qui fait référence à chacune de ses informations - c'est clairement un mécanisme complexe et difficile à rendre robuste aux erreurs. Dans les deux cas, il faudrait gérer les cas d'indisponibilité des référentiels (panne ou maintenance programmée), ce qui ajouterait un niveau de complexité et de risque de dysfonctionnement.
Les propriétés de non-réutilisation et de non-destruction servent à garantir que les identifiants feront bien toujours référence à l'information à laquelle ils doivent faire référence - autrement dit, éviter que la commande de Mme Michu ne soit attribuée plus tard par erreur à M. Martin (c'est essentiel pour la traçabilité légale).
Unicité de la localisation du pilotage des activités

Principe 4 : Unicité de la localisation du pilotage des activités
L'utilisation du système d'information est modélisée sous forme d'activités métier. Une activité métier est une unité de travail, telle que vue par l'utilisateur final, et doit respecter la règle des 4 unités suivante : unité de lieu, unité de temps, unité d'acteur et d'action.
Toute activité métier est pilotée de bout en bout sans délégation par un unique service fonctionnel Pilote (SFP), qui enchaîne des demandes de services à des services fonctionnels Silo.
La première partie du principe se justifie par le besoin pour un système d'information d'entreprise d'un minimum de normalisation et d'homogénéisation des concepts de modélisation au niveau métier et par la cohérence ergonomique qui en découle, ceci pour éviter la création d'un capharnaüm préjudiciable à la fois aux informaticiens et, aussi, aux utilisateurs.
La seconde partie de ce principe est l'équivalent au niveau des traitements de l'unicité de la localisation des informations (principe 3). Sa justification en est similaire : il s'agit de rendre le système d'information modulaire en limitant les couplages forts (on notera que la règle des 4 unités de lieu, de temps, d'acteur et d'action garantit déjà une forte cohérence de l'activité donc un couplage plus faible avec l'extérieur). En effet, éclater le pilotage d'une activité sur plusieurs SFP signifierait que ces SFP se passeraient le relais en cours d'une interaction, interaction qui est pourtant vue par l'utilisateur comme une unité de travail. Pour éviter les ruptures ergonomiques et sémantiques, ce changement de pilote nécessiterait une forte connaissance réciproque des SFP, jusqu'au niveau de l'enchaînement de leurs écrans, et entraînerait donc un couplage fort qui conduirait à complexifier et rigidifier le système d'information - donc à des coûts et des délais de maintenance fortement accrus. D'autre part, les cascades de passages de relais successifs de SFP en SFP rendraient très complexe le traitement des cas non nominaux - en particulier les erreurs. En effet si une erreur (fonctionnelle ou technique) se produisait dans le troisième SFP au bon endroit dans le bon écran, où il est fort possible qu'il faille retourner dans le premier SFP qui est celui qui porte l'enjeu de l'activité. Pour garantir une ergonomie acceptable à l'utilisateur, il faudrait donc introduire un couplage fort entre les différents SFP de la cascade.
Bien entendu, ce principe ne doit pas être utilisé pour recréer un système d'information cloisonné ; le SFP responsable de l'activité doit faire les demandes de services appropriés vers les services fonctionnels Silos appropriés.
Certains traitements ne respectent pas la règle des 4 unités : il s'agit d'enchaînements d'activités soit sur des périodes temporelles différentes soit par des acteurs différents. Ces traitements doivent aussi être pilotés - mais sans introduire de couplage fort entre SF. Pour cela on introduit le protocole de syndication/publication ATOM qui est détaillé en annexe.
Garantie de la cohérence fonctionnelle

Principe 5 : Garantie de la cohérence fonctionnelle
Une information est propriété de son service fonctionnel Silo qui est seul responsable de la garantie de sa cohérence fonctionnelle.
Ce principe peut paraître une simple conséquence du principe d'unicité de la localisation de l'information (principe 3) ; c'est en fait un changement de paradigme fort mais subtil dont les conséquences sont nombreuses.
Dans un système d'information en mode cloisonné, les informations sont totalement gérées par une application, qui connaît tous les traitements pouvant agir sur celles-ci. Le concepteur d'une application peut donc, quand il spécifie un traitement, prendre en compte les besoins des autres traitements de l'application - par exemple, interdire certaines modifications des données qui sont tout à fait correctes dans le cas particulier de ce traitement mais qui introduiraient des incohérences dans d'autres traitements de l'application. Cette approche a montré ses limites : quand l'application grossit, le risque d'oublier une de ces interdépendances cachées devient grand et augmente très significativement les coûts et durées des actions de maintenance évolutive de l'application - au point parfois de figer le système d'information par peur d'introduire des régressions dues à ces interdépendances implicites difficilement maîtrisables.
Dans un système d'information en mode cloisonné structuré en nombreuses petites applications, cette approche tentante est souvent source de gains en durée de réalisation, pourvu que l'on accepte les ruptures applicatives, la duplication des informations et leurs incohérences potentielles - incohérences que l'on peut parfois amoindrir par de gros travaux périodiques dits de remise en cohérence (habituellement tous les quelques mois).
Dans le cadre d'un système d'information d'entreprise structuré autour de référentiels, la limite décrite ci-dessus prend vite toute sa mesure et il est illusoire de croire que l'on pourra construire (et encore moins maintenir) un système d'information basé sur des interdépendances implicites, qui seraient nécessairement en grand nombre (du simple fait de sa taille).
Il est donc nécessaire de rendre explicite toutes les interdépendances. Le lieu le plus adapté pour cela est le service fonctionnel Silo dans sa dimension Référentiel : les services fonctionnels Silos sont donc les seuls garants de la cohérence transverse des informations.
Les conséquences sont multiples.
Règle 5a
Aucun traitement ne peut supposer le respect, même temporaire, d'une règle de cohérence d'un ensemble d'informations si cette règle n'est pas explicitement garantie par un service fonctionnel Silo.
En effet, comme les informations sont accessibles par tous les traitements, rien ne garantit qu'un autre traitement n'ait pas modifié ces informations sans prendre en compte cette contrainte de cohérence - contrainte dont il n'a pas à avoir connaissance. Si cette contrainte est absolument nécessaire pour garantir l'intégrité du traitement (voire du système d'information en entier), alors il faudra durant la phase de conception allouer à un service fonctionnel la responsabilité de la règle de cohérence correspondante. Cette règle de cohérence devra être explicitement et précisément décrite dans la spécification du référentiel (SF Silo).
Il s'agit ici de trouver le bon équilibre entre trop peu de règles dans les référentiels, au risque de ne plus garantir la cohérence transverse du système d'information, et trop de règles dans les référentiels, au risque de faire porter aux référentiels de règles qui ne sont pas fondamentales. Il ne faut pas en particulier que les règles garanties par les référentiels ne soient en totale abstraction avec l'aspect dynamique du monde réel - par exemple le strict respect d'une règle du genre « une situation B est interdite si une situation A s'est produite dans le passé » n'est possible que si l'on oublie que la situation A était peut-être une erreur de saisie.
Règle 5b
Aucun traitement ne peut faire d'hypothèse sur l'histoire d'une information, en dehors de l'historique géré par un référentiel.
Cette règle peut sembler une conséquence simple du rôle transverse des référentiels (par exemple, un autre traitement peut avoir modifié l'information). Elle va cependant à l'encontre d'une habitude des concepteurs d'applications en mode cloisonné qui font souvent des hypothèses du genre : « si tel attribut est à telle valeur c'est que tel traitement l'a positionné et comme je sais que ce traitement vérifie ceci, je peux donc faire cela sans risque ». Dans une approche basée sur des référentiels transverses de telles hypothèses ne sont simplement plus valides car rien ne garantit qu'un traitement a modifié un attribut donné.
S'il est nécessaire de savoir si un certain traitement métier a été appliqué sur une donnée, alors il faut explicitement stocker cette information dans un référentiel (par exemple dans le cadre d'un client, ajouter un attribut signifiant que ses capacités de paiement ont été vérifiées). Un traitement n'a pas à savoir qui, en terme applicatif, a été le support du traitement métier : le fait que l'information soit stockée dans le référentiel lui suffit (sinon on introduirait des interdépendances cachées). Bien sûr, la signification de cette information doit être clairement définie par le référentiel et acceptée par tous.
Ces deux règles s'appliquent même si le traitement est celui qui a créé ces données. Ceci peut paraître évident mais n'est pas intuitif, en particulier pour les concepteurs habitués à des applications en mode cloisonné propriétaires exclusifs de leurs données.
Asynchronisme des pilotes

Principe 6 : Asynchronisme des pilotes (ou l'illusion du temps absolu pour les pilotes)
Les services fonctionnels Pilotes ne peuvent présupposer qu'ils seront synchronisés sur une même base temporelle, en particulier vis à vis de la mise à jour des données des référentiels
Ce principe découle pour partie de la complexité, voir l'impossibilité, de synchroniser un ensemble de processus aussi vaste celui d'une entreprise dans sa globalité et pour partie du besoin de faible couplage entre les différents services fonctionnels.
En effet, la plupart des processus sont souvent initialisés de manière indépendante par des acteurs distincts qui ont des contraintes temporelles différentes. Ces contraintes sont souvent hors du contrôle de l'entreprise (contraintes législatives ou imposées par un acteur externe pour des raisons commerciales). Par exemple, un avis d'imposition doit être envoyé à l'adresse connue de l'usager au moment de la signature du rôle mais un usager peut demander un changement d'adresse entre la signature du rôle et l'émission de l'avis.
Une solution tentante consisterait à interdire les demandes de changement d'adresse pendant les périodes entre la signature des rôles et l'émissions des avis. Ceci imposerait une contrainte forte à l'usager - contrainte qui n'est pas conforme à la volonté actuelle de l'Administration Fiscale. D'autre part, il faudrait vérifier qu'aucun autre processus nécessitant ce changement d'adresse n'interviendra durant cette période. Il est clair que l'on introduirait un couplage fort entre les processus, couplage qui conduirait à une rigidité forte du système d'information et des processus métier.
Il est important de noter que ce phénomène est une conséquence intrinsèque de la mise en place des référentiels transverses ; les applications en mode cloisonné qui gèrent leurs propres copies des informations n'ont pas ce genre de problèmes, mais au prix d'une incohérence des informations et d'un service dégradé pour l'entreprise, ses clients ou ses partenaires. Il ne sert donc à rien d'essayer de combattre ce phénomène, mais il s'agit bien de l'accepter car la solution est simple : il suffit de garder un historique de toutes les modifications des informations des référentiels. Avec cet historique, le processus de changement d'adresse peut s'exécuter à tout moment car le pilote en charge de la création de l'avis demandera au référentiel non pas la dernière adresse connue de l'usager mais bien son adresse au moment de la signature du rôle fiscal.
Ceci se résume dans la règle suivante :
Règle 6a
Toutes les modifications des informations des référentiels sont placées dans un historique.
Cette historique impose à tous les silos de partager une base de temps commune, c'est à dire une horloge commune. D'un point de vue technique les mécanismes correspondants existent et sont simples à mettre en oeuvre (serveurs de temps).
Cette règle s'applique aussi, en conjonction avec la règle de non-destruction des identifiants, à la suppression des données :
Règle 6b
Les informations ne sont pas détruites mais marquées comme invalides à partir d'une certaine date.
Cette règle soulève la question des purges et des archivages. Les concepts de purge et d'archivages sont liés aux contraintes physiques des supports de stockage de masse (disques durs) : ces supports avaient auparavant des capacités très limitées nécessitant de purger et d'archiver les données les plus anciennes ou peu utilisées. Ceci imposait la mise en place de mécanismes complexes, en particulier pour rapatrier les données archivées en cas de besoin et pour les purger à nouveau. Ces mécanismes, déjà compliqués dans le cadre d'une application dans un système d'information cloisonné, deviennent extrêmement complexes dans le cadre de l'ensemble d'un système d'information d'entreprise centré sur des référentiels transverses.
La très forte augmentation des capacités des systèmes de stockage permet actuellement de se passer de ces mécanismes dans la plupart des cas et donc de simplifier très significativement la conception du système d'information. D'autre part, la généralisation des obligations d'audit (traçabilité industrielle ou contraintes de type Sarbanes-Oxley) imposent la non destruction de la plupart des données historiques de l'entreprise.
Une attention particulière doit être mise dans les cas où la destruction réelle des informations est une obligation légale forte (par exemple les contraintes CNIL) ; il s'agit alors de vérifier l'impact de cette obligation sur l'ensemble des processus.
Une autre conséquence de ce principe est la préconisation de permettre l'activation simultanée des traitements conversationnels et non conversationnels (les travaux par lots [batch]). En effet, il est habituel de réserver les traitements non conversationnels pour la nuit, en dehors des heures de travail quand les ressources matérielles (les machines) ne sont pas utilisées par les traitements conversationnels. Ceci permet d'optimiser l'utilisation des ressources matérielles.
Cette règle de bon usage des ressources s'est souvent transformée au fil du temps en une règle fonctionnelle et les concepteurs ont souvent tiré parti de cette exclusion pour faciliter la rédaction des spécifications fonctionnelles. Ceci est clairement un couplage entre processus, dont nous avons vu les inconvénients.
De plus, dans le cadre de référentiels transverses géographiques, le territoire couvert par un pilote peut être dispersé sur plusieurs fuseaux horaires, ce qui impose un large étalement des horaires de disponibilité des traitements conversationnels. Les exclusions fonctionnelles entre traitements conversationnels et non conversationnels imposent donc :
- soit de réduire très fortement la fenêtre temporelle disponible pour les traitements non conversationnels,
- soit de demander aux employés de certains pays de travailler hors des horaires habituels dans leur pays.
Ce phénomène est encore amplifié par l'Internet où l'expérience a montré que les internautes exigent une plage d'ouverture des services très étalée, voire continue (24h sur 24h et 7 jours sur 7).
Ceci justifie donc la règle suivante :
Règle 6c
Les activités doivent être modélisées de manière à permettre l'activation simultanée des activités conversationnelles et des activités non conversationnelles.
Cette règle qui peut paraître contraignante est en fait simple à mettre en oeuvre grâce à l'historisation des données (règle 6a) et au concept classique de date de valeur (celui qui est utilisé par toutes les banques et que l'on retrouve sur les relevés bancaires que nous recevons tous).
Non-exclusivité des données

Principe 7 : Non-exclusivité des données (même de manière temporaire)
Les services fonctionnels Pilotes ne peuvent réserver, même de manière temporaire, un accès exclusif à une donnée d'un référentiel.
Ce principe est en fait très similaire au principe d'asynchronisme (principe 6), avec une dimension supplémentaire liée à la complexité des données.
Dans les applications en mode cloisonné, la gestion des potentiels conflits d'accès entre plusieurs utilisateurs sur une même donnée est généralement faite via des mécanismes de réservation : l'utilisateur annonce son intention de travailler sur une donnée et l'application en interdit l'accès (au moins en modification) aux autres utilisateurs. Ce mécanisme de verrouillage des données est généralement mis en oeuvre quand l'activité de l'utilisateur est relativement longue : de quelques heures à quelques jours.
Dans le cas d'un système basé sur des référentiels transverses, une telle réservation impliquerait qu'aucun autre processus de l'ensemble du système fiscal ne pourrait modifier cette donnée. Cette réservation, qui était voulue et acceptable sur une sous-partie du système d'information, prend une ampleur difficilement contrôlable quand elle s'applique sur l'ensemble du système. En effet la sémantique de la réservation devient vite complexe à définir précisément et entraîne rapidement un couplage fort entre processus -couplage dont nous avons vu les inconvénients majeurs.
Prenons l'exemple d'un contribuable dont on est en train de changer la situation fiscale. Cette modification peut prendre plusieurs minutes voir plusieurs heures, en particulier si l'agent est interrompu (téléphone) ou si l'agent doit chercher des informations supplémentaires. On pourrait donc vouloir 'réserver' les données du contribuable pour éviter que quelqu'un d'autre ne les modifie en même temps ou n'applique des traitements sur ces données en cours de modifications.
Mais où pourrait être stockée cette 'réservation' ? Si elle était stockée dans le SF pilote de l'activité qui réserve, alors soit il faudrait introduire un couplage fonctionnel fort entre les SF, soit les processus des autres SF n'appliqueraient pas cette 'réservation' et pourraient donc modifier les données, ce qui rendrait inutile la réservation. Il faudrait donc stocker cette réservation dans le référentiel propriétaire de la donnée.
D'autre part, quel serait le périmètre d'application de cette 'réservation' : le client, son adresses, ses moyens de paiement, ses commandes - en lecture ou en écriture ? Devrait-on refuser une demande de changement d'adresse d'un client sous prétexte que l'on est en train de traiter une commande ? Devrait-on refuser un paiement ?
Ensuite, se pose la question de la durée de la réservation : une réservation bloquée depuis longtemps est-elle due au fait que le traitement qui a posé la raison de la réservation est toujours valide (attente d'information par courrier) ou bien au fait que l'utilisateur a été interrompu et va bientôt continuer ou bien au fait qu'il a complètement oublié. Pour gérer le dernier cas, il serait tentant de mettre en place un mécanisme de libération de réservation. Le mécanisme simple qui consiste à tout libérer tous les soirs n'est adapté qu'aux cas où l'objectif de la réservation est limité dans le temps, ce qui exclut tous les cas de réservation liée à la cohérence des données. Dans les autres cas, il faudrait mettre en place des mécanismes complexes, par exemple envoyer des messages à l'utilisateur pour lui demander de libérer les données ou annuler toutes les modifications faites par cet utilisateur.
Comme on le voit, cette simple volonté de réserver une donnée engendre une énorme complexité fonctionnelle et/ou des contraintes métier fortes. Il faut donc comparer le gain obtenu par rapport à une situation où la donnée n'est pas réservée. Or les objectifs annoncés de telles réservations sont doubles :
- Garantie d'une cohérence : Il s'agit de garantir une règle de cohérence fonctionnelle considérée comme importante par le processus qui réserve la donnée et dont il ne veut pas qu'elle soit perturbée par un autre processus. Comme cette réservation est temporaire, rien ne garantit que cette règle sera respectée ensuite par les autres processus : la réservation n'apporte donc aucune garantie réelle. Comme nous l'avons vu dans le principe de gestion de la cohérence (principe 5), si une règle de cohérence doit être respectée par tous alors elle doit être garantie de manière permanente par un référentiel et la réservation est alors inutile.
- Gestion d'une incohérence temporaire : Il s'agit de permettre de manière temporaire le non respect d'une règle de cohérence garantie par le référentiel. Il est donc nécessaire de bloquer l'accès à la donnée pour 'cacher' ce non-respect temporaire et éviter que d'autres processus appliquent des traitements sur des données incohérentes. Dans ce cas, on voit bien que l'on est en train d'essayer de dévoyer le principe 5 ci-dessus : la garantie de la cohérence par les référentiels. Il est alors beaucoup plus simple de garder cet état intermédiaire incohérent dans le SF pilote et de mettre à jour les référentiels dès que les données sont cohérentes du point de vue du référentiel. Il est important ici de noter qu'il ne s'agit pas d'attendre que les données soient cohérentes du point de vue du pilote - nous avons vu au paragraphe précédent que c'était inutile - mais bien du point de vue du référentiel de manière à ne pas recréer des applications en mode cloisonné et à rendre au plus tôt les données disponibles à tous les processus.
Les objectifs de la réservation de données, qui semblaient importants à première vue et qui pouvaient être utiles dans système d'information en mode cloisonné, ne sont donc plus pertinents dans une approche basée sur des référentiels transverses.
Il est à noter que ce principe entraîne des évolutions dans l'ergonomie de certains traitements : la structuration du système d'information autour de grands référentiels transverses impose une évolution du dialogue homme-machine pour passer d'une logique où l'utilisateur se voit refuser une activité a priori car la donnée est verrouillée à une logique où il se voit demander son avis a posteriori en cas de conflit. Ceci est détaillé dans l'annexe « Optimistic locking ».
Enfin, il est important de noter que ce principe s'applique aussi pour le traitement qui a créé la donnée. Ceci peut paraître évident mais n'est pas intuitif pour les concepteurs habitués à des applications en mode cloisonné propriétaires exclusifs de leurs données.
Services sans états

Principe 8 : Services sans états
Les services fonctionnels Silo fournissent des offres de services sans état - laissant toujours le référentiel dans un état cohérent.
Le concept de « service sans état » signifie que chaque activation du service est traitée de manière indépendante sans référence aux précédentes activations des services du SF (autrement bien sûr que via les données stockées dans le référentiel). En clair, on doit fournir à chaque appel du service toutes les données nécessaires pour traiter la demande.
Cependant, tous les services fonctionnels Pilotes traitent un enchaînement d'activités. Ils apparaissent donc comme des services avec état, c'est à dire des services qui s'inscrivent dans le cadre d'une session et dont les résultats dépendent des services précédemment invoqués dans la session. Le SF devrait garder et gérer localement un état pour chacun des clients connectés. Un exemple de session est illustré par un site de commerce en ligne où l'utilisateur se connecte et ouvre une session, se 'promène' sur le site et dépose des articles dans son caddie ; le contenu du caddie est maintenu entre les différentes invocations du service de dépose d'un article mais il disparaît à la fin de la session.
Dans le cadre des interactions avec un humain, le concept de session est souvent nécessaire pour offrir une ergonomie appropriée aux activités des utilisateurs.
Comment peut-on maintenir une session en respectant le principe 8 de Service sans état ?
Il existe de nombreuses solutions dont la description détaillée dépasse le cadre de ce document. Dans une architecture REST, la manière la plus naturelle consiste à maintenir l'état de l'application sur le poste client dans un URI ou dans un ensemble d'URI. Si le volume de données de session est important ou si on veut maintenir l'état au-delà de la session sur le poste client, il suffit de créer un URI temporaire dans un service de persistance.
Dans le cadre des services offerts par les SF Silo, il s'agit d'une session purement informatique entre deux éléments logiciels. De telles sessions et les protocoles d'interaction associés sont relativement complexes à spécifier car il faut définir les ressources qui seront visibles dans la session mais pas hors de la session et définir les services liés à la gestion de la session (ouvrir, fermer, annuler, reconnecter, etc...) ; il faut aussi faire le lien entre les ressources et les services de gestion de session, sans oublier les cas inhabituels (par exemple, que faire si une session est ouverte sans activités depuis longtemps : la laisser ouverte indéfiniment au risque de bloquer des ressources inutilement si l'initiateur de la session a oublié de la fermer ou la fermer au risque de perdre les données de la session ?).
Au niveau technique, la gestion des sessions consomme des ressources matérielles. Cette consommation, qui était relativement facile à maîtriser dans un système cloisonné au niveau applicatif et géographique, deviendrait difficilement contrôlable dans un système basé sur des référentiels transverses. En effet, chaque SF Silo devrait alors être capable de gérer potentiellement des sessions pour tous les SF Pilotes et pour tous les traitements de l'ensemble des utilisateurs. Le nombre de session à gérer simultanément par un SF Silo serait une combinaison du nombre d'utilisateur (plusieurs dizaines à plusieurs centaine de milliers d'utilisateurs pour une grande entreprise) et du nombre de traitements qu'un utilisateur peut dérouler en parallèle (habituellement 2 à 3). On voit que les ressources matérielles à mettre en oeuvre seraient très significatives.
Or l'utilisation de sessions correspondrait aux objectifs suivants :
- permettre une réservation temporaire d'une donnée ou d'un ensemble de données pendant la durée de la session
- permettre de créer des états temporairement incohérents d'une donnée ou d'un ensemble de données pendant la durée de la session
Nous avons vu ci-dessus que ces objectifs ne sont plus pertinents dans un système d'information basé sur des référentiels transverses. Il n'est donc pas utile, et même contre-productif, d'autoriser les SF Silo à fournir des services à état. Ceci justifie la première partie du principe ci-dessus.
La seconde partie du principe est une conséquence simple du rôle de garant de la cohérence fonctionnelle des données par les services fonctionnels Silo : à tout moment les informations du SF Silo, telles que visibles par les autres SF via les services, doivent respecter les règles de cohérence garanties par le SF.
Ce principe a une conséquence importante sur la structure et la granularité des services exportés par un SF :
Règle 8a
Les services exportés par les SF Silo sont atomiques et de granularité moyenne.
Les services sont atomiques dans le sens où chaque service est traité de manière complète insécable. Si au niveau technique un service fonctionnel Silo peut traiter en parallèle plusieurs services, au niveau fonctionnel tout se passe comme si les services étaient traités les uns après le autres - en particulier, si l'exécution d'un service d'un SF nécessite la mise à jour de plusieurs objets du référentiel de ce SF, alors un service de lecture ne pourra s'insérer au milieu de ces écritures.
Les services sont de granularité moyenne dans le sens où une granularité trop fine ne permettrait pas de garantir que les règles de cohérence fonctionnelle sont toujours garanties. Par exemple, si une règle de cohérence porte sur plusieurs objets, alors un service permettant la mise à jour simultanée de ces objets est nécessaire - car sinon il faudrait plusieurs demandes de services pour retrouver un état cohérent et on créerait un état potentiellement incohérent entre les différentes invocations des services.
Il est important de noter dans cette règle que atomique ne veut pas dire minuscule mais bien insécable. Il n'y a donc pas de contradiction entre services atomiques et services de granularité moyenne : dans un système d'information centré sur des référentiels transverses les services sont de 'gros atomes'.
Comment traiter la validation à deux phases ?

La deuxième objection souvent faite pour justifier des Services avec état est la « validation à deux phases » (two phase commit).
Supposons qu'un SF Pilote nécessite l'enchaînement de deux SF Silos, par exemple, l'enregistrement d'une commande suivi d'un paiement. L'enregistrement de la commande modifie l'état des stocks de manière permanente. Que faire si le paiement n'est pas accepté par la banque ?
Il existe au moins 4 méthodes :
- Abandonner. C'est la solution la plus simple. Elle n'est pas toujours possible comme dans l'exemple choisie car l'état des stocks serait incorrect.
- Recommencer. C'est une solution à n'employer que si elle a une chance raisonnable de succès. Si le serveur de la banque a répondu que la carte était en opposition, il ne sert à rien de réessayer.
- Compenser. La compensation peut être automatique, au bout d'un certain délai ou sur demande explicite d'annulation de commande. C'est la bonne solution dans ce cas.
- Coordonner. Faire une ressource temporaire qui assure la synchronisation. Cette méthode n'est pas recommandée car on introduit à nouveau des couplages forts entre ressources.
Référentiels passifs

Principe 9 : référentiels passifs
Un service fonctionnel Silo (référentiel) n'a pas vocation à avertir les autres SF Silo des modifications de ses données.
Les raisons de ce principe sont multiples.
Tout d'abord nous avons vu que le pilotage des activités et des processus métiers était dévolu aux services fonctionnels Pilotes. Avertir pour action un autre service fonctionnel d'une modification d'une donnée est un morceau de processus qui doit donc être piloté par un service fonctionnel Pilote pas par un service fonctionnel Silo.
D'autre part, la diffusion d'information par ce genre de mécanismes (dit de push) imposerait la mise en place de protocoles complexes pour traiter correctement de manière robuste les impondérables de la vie réelle. En effet, lors de la mise à jour de la donnée, il est possible qu'un des services à avertir ne soit pas disponible (panne machine ou maintenance programmée). Il ne faut pas oublier que la haute disponibilité coûte très cher en développement et en exploitation et qu'il faut la réserver aux composants pour lesquels il existe une réelle justification métier. Il faudrait donc définir un mécanisme permettant de réémettre les avis de modification tout en garantissant que les avis ne peuvent pas être dupliqués (imaginez les conséquences de la duplication d'un ordre de débit d'un compte).
Il faudrait aussi définir les règles de diffusion, car avertir tous les services de toutes les mises à jour de toutes les données demanderait une bande passante et une capacité machine astronomique. En effet il ne faut pas oublier que dans une approche basée sur des référentiels, le taux de mise à jour par référentiel est bien plus élevé que dans le cas d'un système cloisonné par application et par géographie. Afin de respecter le principe de couplage faible entre processus de services différents, il serait nécessairement à la charge des différents services fonctionnels d'indiquer au référentiel les données dont les modifications les intéressent ; ce mécanisme d'abonnement ajouterait encore à la complexité des protocoles à définir.
Il est donc beaucoup plus facile de mettre en place dans les référentiels des méthodes qui permettent aux services pilotes de connaître les données qui ont été modifiées sur une période de temps donnée. C'est donc à chaque service Pilote, d'utiliser ces méthodes et d'accéder aux historiques des modifications (cf. règle 6a).
Dans beaucoup de cas, ces mécanismes peuvent se simplifier par l'emploi d'un standard de publication des modifications. Prenons l'exemple des flux ATOM (RSS) sur l'Internet. Chaque site qui modifie ses informations met simultanément à jour son ou ses flux ATOM (RSS). Un service qui doit être informé des modifications va « s'abonner » à ce flux, c'est à dire le lire quand il en a besoin. Il pourra alors détecter une mise à jour et la traiter. Il y a découplage total entre le SF producteur qui publie à son rythme et le SF consommateur qui va lire à son rythme.
Ceci se résume dans la règle suivante :
Règle 9a
Les SF Silo (référentiels) doivent fournir des services ou des flux permettant aux SF Pilotes de connaître les données qui ont été modifiées.
Il est à noter que ces services sont très simples à définir et à réaliser dès lors que les informations existent dans des historiques (règle 6a).
Il faut aussi noter que ces flux peuvent être générés dynamiquement « à la demande » pour générer facilement des alertes. Par exemple un moteur de recherche peut renvoyer les résultats sous la forme d'un flux ATOM. Une modification du résultat détectée par un SF permet de générer une alerte.
Annexe 1 : le style d'architecture REST
Voici quelques définitions précises, pour la plupart extraites du MDA de l'OMG.
Architecture d'un système
L'architecture d'un système est définie par un ensemble de classes d'éléments et par les contraintes appliquées à ces éléments.
Les classes d'éléments d'une architecture regroupent :
- les composants logiciels ;
- les connecteurs (propriétés externes de ces composants) ;
- les relations entre les composants et les connecteurs.
Les contraintes sur les éléments sont définies en fonction des caractéristiques attendues d'une architecture comme maximiser l'indépendance ou l'extensibilité, minimiser les temps de réponse, faciliter la réutilisation, etc...
Service
C'est une fonction logicielle autonome [self contained] qui accepte des requêtes et qui renvoie des réponses au travers d'une interface standard bien définie.
Les technologies employées pour réaliser un service comme le langage de programmation ne font pas partie de la définition d'un service.
Services sans état [Stateless]
Toutes les données nécessaires au traitement sont fournies à l'appel du service qui renvoie une réponse sans conserver d'état. C'est une contrainte forte pour garantir l'extensibilité et la réutilisation.
Comment réaliser des applications avec état avec des services sans état ?
Le plus simple consiste à conserver l'état de l'application chez le client. Le système est alors extensible car indépendant du nombre de clients. Si l'état doit persister au delà d'une session, il faut conserver l'état dans des données persistantes.
Modèle [pattern]
Un modèle [pattern] est défini par Martin Fowler ("Analysis Patterns", 1997) comme "une idée qui a été utile dans un contexte particulier et qui le sera probablement dans d'autres contextes".
Cette notion de modèle est valide à tous les niveaux, depuis le morceau de code qui résout un problème particulier jusqu'à un groupe de fonctions dans un domaine comme les télécommunications ou la comptabilité.
Style d'architecture
Un style d'architecture est une classe d'architectures de systèmes qui ont des modèles communs.
Un style d'architecture définit une famille de systèmes en terme de modèles de structure, un vocabulaire de composants et de connecteurs et des règles ou contraintes sur leurs relations.
L'évolution des styles d'architecture est généralement liée à l'évolution de la technologie.
Architectures orientées service [SOA]
SOA est un style d'architecture qui se définit par :
- un couplage lâche [loose coupling] entre les composants logiciels
pour ne pas dépendre de l'état d'autres services et pour faciliter la réutilisation - des services sans état [stateless scalabilty] et l'éventuelle orchestration
- des services fortement interopérables
ce qui implique l'utilisation de vocabulaires de données très bien définis.
Historique de REST
REST est l'acronyme de "Representational State Transfer" inventé par Roy T. Fielding dans sa dissertation "an architecture style of networked systems". Roy T. Fielding participe depuis 1994 aux travaux du W3C sur les sujets URI, HTTP, HTML et WebDAV et a été le co-fondateur du projet Apache, le serveur Web qui équipe 60% des sites Web de tout l'Internet. REST décrit les caractéristiques du Web qui en ont fait son succès. L'explication de la signification de REST telle que donnée par Roy T. Fielding est la suivante
"Representational State Transfer évoque l'image du fonctionnement d'une application Web bien construite : un réseau de pages Web (une machine à états finis virtuelle) où l'utilisateur progresse dans l'application en cliquant sur des liens (transition entre états) ce qui provoque l'affichage de la page suivante (représentant le nouvel état de l'application) à l'utilisateur qui peut alors l'exploiter".
REST, un style d'architecture
REST est un style d'architecture, pas un standard. Il n'existe donc pas de spécifications de REST. Il faut comprendre le style REST puis concevoir des applications ou des services Web selon ce style.
REST concerne l'architecture globale d'un système. Il ne définit pas la manière de réaliser dans les détails. En particulier, des services REST peuvent être réalisés en PHP, .NET, JAVA, COBOL ou autre.
Bien que REST ne soit pas un standard, il utilise des standards. En particulier :
- URI comme syntaxe universelle pour adresser les ressources ;
- HTTP comme protocole de communication ;
- Des liens hypermedia dans des documents (X)HTML et XML pour représenter à la fois le contenu des informations et la transition entre états de l'application,
- Les types MIME comme text/xml, text/html, image/jpeg, application/pdf, video/mpeg pour la représentation des ressources.
Les contraintes du style REST
Le style REST s'exprime par des contraintes sur l'architecture. Chaque contrainte procure des avantages ![]() et des inconvénients
et des inconvénients ![]() . Les principales contraintes sont :
. Les principales contraintes sont :
- Client-Serveur
 Séparation entre interface utilisateur et données ; Evolution indépendante des composants.
Séparation entre interface utilisateur et données ; Evolution indépendante des composants. - Sans état [Stateless]
Visibilité : chaque requête révèle tout ; Fiabilité : il est facile de réparer une erreur ; Extensibilité [scalability] : l'état du service ne dépend pas ni de la requête ni du nombre de clients.
Charge réseau : augmente le nombre ou la taille des requêtes. - Cache
Rendement [Efficiency] du réseau : élimine des interactions ; Extensibilité : les clients ont le "droit" d'utiliser des données en cache ; Performances : l'utilisateur perçoit un temps de réponse plus rapide.
 Données en cache : quelquefois périmées.
Données en cache : quelquefois périmées. - Interface uniforme
Identification des ressources ; manipulation des ressources par des représentations ; messages auto-descriptifs ; hyperliens pour maintenir l'état de l'application ; Simplicité : nombre limité d'opérations ; Découplage entre application et interface.
Performances : adaptation aux interfaces. - Système en couches
Simplicité : le système peut être construit par étapes ; Sécurité : encapsulation de systèmes existants.
Performances : augmentation des appels système. - Code sur demande
Simplification du client ; Evolutivité.
Les éléments du style REST
Les principaux éléments du style REST sont les données (ressources), les connecteurs (HTTP) et les composants (clients, serveurs, cache, proxies).
Ressource
Une ressource est tout ce qui peut être nommé : un document, la météo de Paris, une collection d'autres ressources.
Une ressource est nommée par un identificateur de ressources [Uniform Resource Identifier - URI].
L'état actuel de la ressource peut être obtenu par une représentation.
Une représentation est composée de métadonnées et de données. Habituellement, les métadonnées sont celles du protocole HTTP et les données sont représentées par des types MIME, le plus utilisé étant le XML
Connecteurs
Un connecteur est une interface abstraite entre les composants pour communiquer par un réseau. Le connecteur habituel du style REST est le protocole HTTP. C'est un protocole sans état [stateless] avec un nombre très limité d'opérations (GET, POST, PUT, DELETE) et une grande richesse de métadonnées.
Composants
Les composants "exécutent" les requêtes et les réponses.
Par exemple, un agent utilisateur [user agent] envoie des requêtes et traite les réponses. Si c'est un navigateur, il présente les résultats contenus dans la réponse.
Un serveur reçoit des requêtes et fournit les représentations des ressources demandées.
Un serveur mandataire [proxy] agit à la fois comme un client et comme un serveur.
Le travail de l'architecte
Le premier travail consiste à identifier et à nommer les ressources (au lieu de définir des API !). En aucun cas un URI ne doit être la conséquence d'un développement.
- Il faut bien sûr préférer un nommage logique http://www.example.com/message/1234 à un nommage physique http://www.example.com/message.asp?numero=1234 pour masquer une implémentation spécifique.
- Les ressources doivent être identifiées par des noms, pas par des verbes. Les ressources représentent des états, pas des actions. C'est d'ailleurs la grande différence avec des techniques du type RPC ou Objet qui détaillent à l'infini des actions (méthodes).
- Les URI ne doivent pas changer car vous ne saurez jamais qui détient des vieilles références : liens dans d'autres pages, utilisateurs dans leurs favoris, notes sur un bout de papier. Il faut donc intégrer si nécessaire le numéro de version dans l'URI.
- Le contenu des bases de données ou les entités métiers doivent avoir des URI. Tout navigateur devient un client du pauvre très utile pour les tests. Les références peuvent se trouver dans d'autres médias comme des messages ou de la documentation. Le XSLT devient utilisable pour présenter, inclure ou transformer les données XML.
- La toute puissance du HTTP GET et de la représentation hypermédia permet grâce à des liens de construire la navigation ou de fournir progressivement des détails. L'état d'une application est donné par une URI.
- C'est le client qui tire les représentations des ressources. Chaque requête doit comporter toutes les indications nécessaires pour son exécution et ne doit pas s'appuyer sur un contexte stocké sur le serveur. Tous les services de l'application doivent donc être sans-état (stateless).
- La représentation des données doit s'appuyer sur des standards comme utf-8 pour le jeu de caractères, le XML ou le XHTML pour la syntaxe des documents et des vocabulaires spécifiques (Dublin Core, RSS, Atom...) pour la sémantique des données. C'est le rôle de l'architecte de bien spécifier tous les standards de l'application.
Il faut noter que l'URI logique ne contient pas d'indication sur la manière dont chaque ressource élabore ses réponses. C'est ce qu'on appelle un couplage lâche [loosely coupled]. C'est un principe général d'architecture des systèmes informatiques trop souvent oublié qui devient "naturel" avec REST.
Annexe 2 : [Optimistic locking]
Comme nous l'avons vu au de non-exclusivité des données (principe 7), il n'est pas possible de réserver même temporairement une donnée. Une conséquence de ce principe est qu'une donnée peut potentiellement être modifiée par un utilisateur pendant qu'un autre utilisateur est en train de l'éditer.
Supposons par exemple que l'utilisateur veuille modifier l'adresse d'un client. Il effectue pour cela une activité dans le SF Pilote approprié. Il est fort probable que l'interface homme machine pour cette activité affiche un ensemble d'information sur le client, dont l'adresse courante. Notre utilisateur commence à saisir la nouvelle adresse mais il est interrompu par un appel téléphonique. Pendant ce temps un autre utilisateur effectue une activité qui a pour conséquence de modifier l'adresse du client. Notre premier utilisateur qui reprend son activité à la fin de sa conversation téléphonique n'est pas au courant de la modification faite par l'autre utilisateur et risque donc de l'écraser.
En général, ceci ne pose pas de problème fonctionnel, car le résultat habituellement est le même que dans le cas tout à fait valide où le second utilisateur avait fait sa modification en premier, par exemple quelques minutes avant que le premier utilisateur ne commence.
Dans certains cas, le traitement fait par le pilote dépend de la valeur initiale de la donnée. Il est alors important de vérifier avant les mises à jour dans les SF Silo que la valeur n'a pas changé durant le traitement de l'activité par l'utilisateur. La solution classique pour traiter ce genre de scénario consiste à introduire dans le service de modification d'une donnée la dernière valeur connue par le pilote. Le SF Silo compare celle-ci avec la valeur courante dans le référentiel ; en cas de divergence, une erreur est retournée au pilote qui peut alors, si nécessaire, afficher un message à l'utilisateur indiquant que la valeur a été modifiée entre temps et lui demandant, par exemple, la conduite à tenir.
Il convient cependant de relativiser la fréquence et l'importance de ces cas :
- La fréquence de tels conflits sera rare, et bien moindre que celle des refus a priori par verrouillage, car comme nous l'avons vu au principe 7, l'approche par réservation impose un périmètre de verrouillage assez large puisque l'on ne sait pas a priori où pourrait intervenir le conflit.
- En général les activités ne sont pas en réel conflit - dans l'exemple des adresses ci-dessus il est très probable que les adresses entrées par les deux utilisateurs seront les mêmes car un contribuable habite à une seule adresse (le fait que deux activités ont été lancées est sûrement dû à l'activation par le client de deux filières de changement d'adresse - par exemple une déclaration au registre du commerce et une saisie directe via un formulaire en ligne sur le site web de l'entreprise).
- Dans les cas de réel conflit, ce conflit aurait dû être traité de toute façon - il n'y a donc globalement ni charge supplémentaire vers les utilisateurs ni augmentation du périmètre applicatif. Au contraire, la potentialité d'une incohérence est détectée plus vite et peut être résolue avant que les conséquences ne se propagent dans le reste du système d'information.
La structuration du système d'information autour de grands référentiels transverses impose donc une évolution du dialogue homme-machine pour passer d'une logique où l'utilisateur se voit refuser une activité a priori car la donnée est verrouillée à une logique où il se voit demander son avis a posteriori en cas de conflit.
Annexe 3 : Les alertes, les affaires et les indicateurs métier
Certains traitements ne respectent pas la règle des 4 unités : il s'agit d'enchaînements d'activités soit sur des périodes temporelles différentes soit par des acteurs différents. Ces traitements doivent aussi être pilotés - mais sans introduire de couplage fort entre les services fonctionnels. Pour cela on introduit les concepts d'alertes et d'affaires, qui sont détaillés ci-dessous.
Les traitements qui ne respectent pas la règle des 4 unités, sont des enchaînements d'activités présentant des discontinuités :
- Discontinuités temporelles : c'est le cas où il existe des interruptions inévitables dans le déroulement du traitement - par exemple, quand il faut demander des informations complémentaires à un client.
- Discontinuités d'acteurs : c'est le cas où un acteur n'est pas habilité pour l'ensemble d'un traitement - par exemple, un employé d'un centre d'appel enregistre une demande d'un client, qui sera prise en compte par un autre employé ayant la qualification et l'habilitation appropriée.
- Discontinuités d'actions : c'est le cas où un ensemble d'acteurs exécutent un ensemble d'actions non strictement synchronisées, dans le cadre d'un macro-processus - par exemple la gestion des campagnes promotionnelles qui regroupe des activités de définition des tarifs, de saisies des commandes, de bilan de la campagne, etc.
Dans de nombreuses organisations, l'affectation des traitements se fait au niveau des structures et pas au niveau de l'employé. Les traitements sont routés à une structure et c'est le chef de cette structure qui les affecte à un employé (ou ce sont les employés qui piochent dans la liste de traitements affectée à la structure).
Tous ces traitements doivent aussi être pilotés - mais sans introduire de couplage fort entre SF. Pour cela on introduit le concept d'alerte.
Une alerte permet à une activité de demander l'activation ultérieure d'une autre activité dans un contexte donné. Les alertes sont routées automatiquement de manière asynchrone vers la structure appropriée puis affectée à un employé; un contexte attaché à l'activité permet à l'employé de connaître les paramètres de l'activité (en particulier l'identification du client). Afin de ne pas introduire de couplage fort et de respecter les 4 règles d'unicité, l'activité émettrice de l'alerte ne s'intéresse pas au résultat de l'alerte ; c'est la responsabilité de l'activité liée à l'alerte de prendre en charge l'ensemble des traitements nécessaires, au besoin via la création d'une autre alerte.
Conformément à la règle 3b ci-dessus, le contexte d'une alerte est constitué d'un ensemble d'URI- les valeurs associées sont donc stockées au préalable dans un référentiel (sinon il faudrait que le système de routage des alarme ait une connaissance intime de la structure interne de l'ensemble des données du système d'information, avec toutes les conséquences que l'on connaît en terme de coûts et délais de maintenance).
Le concept d'alerte induit un certain couplage entre activités et donc entre les SF pilotes dans le sens où une activité (et donc son SF pilote) est autorisée à connaître les autres activités automatisées par le Système d'Information, y compris dans d'autres SF. Ce couplage reste cependant relativement lâche et est considéré comme acceptable.
Dans certains cas, il est important de suivre l'enchaînement des diverses activités. Par exemple, le traitement d'un contentieux avec un client pourra mettre en oeuvre des activités de plusieurs employés ; il faut pouvoir coordonner ces activités et pouvoir disposer à tout moment d'un rapport sur l'état d'avancement de cet ensemble d'activités. Il faut dans ce cas créer une affaire qui regroupe l'ensemble des informations nécessaires au traitement et au suivi de ce traitement. Ces affaires sont des données métier comme les autres ; elles sont donc propriété d'un SF silo et sont mises à jour par les diverses activités associées au traitement. La coordination des différentes activités est aussi une activité (conversationnelle ou non conversationnelle) qui à partir des informations associées à l'affaire peut demander, via le mécanisme des alertes, l'activation des activités nécessaires au traitement de l'affaire.
Il existe bien évidemment, dans un système d'information de la complexité d'un SI d'entreprise, plusieurs types d'affaires qui ont peu en commun : le traitement d'un contentieux de paiement n'a rien à voir avec le traitement de création d'un client.
Dans le cas des macro-processus, il faut pouvoir en suivre l'avancement global. On utilise pour cela des indicateurs métiers - par exemple, le nombre de commandes en cours, le nombre d'impayés, le volume de vente d'un produit, etc. Ces indicateurs sont des données métier comme les autres : ils sont propriétés d'un SF Silo, sont mis à jour par les diverses activités et sont consultables par des activités suivant différents format suivant l'objectif visé par l'activité (par exemple affichage du nombre total de commandes pour information commerciale, affichage du nombre de commandes à traiter pour pilotage de l'activité des employés, etc...).
Il est important de noter que le concept d'alertes est lié à l'organisation du travail en correspondance avec la structuration de l'organisation ; la structuration des alertes et les mécanismes de routage sont donc indépendant de tout concept métier - ceci justifie que toutes les alertes soient gérées par un unique SF transverse, permettant de garantir la forte cohérence du concept (par exemple, concentrer les impacts à un seul SF en cas de changement de mode d'organisation).
Au contraire pour les affaires et les indicateurs, leur diversité et le manque de points communs à la fois dans leur structuration et dans leurs logiques justifient que les différents types d'affaire et d'indicateurs soient gérées par des SF spécifiques, permettant de garantir la faible couplage entre les différents types (par exemple, pouvoir modifier le traitement des affaires de contentieux de paiement sans impacter le traitement des contentieux de commande).
Ajoutez vos commentaires ci-après ou les envoyer à Jean-Paul Figer

Ce(tte) œuvre est mise à disposition selon les termes de la Licence Creative Commons Attribution - Pas d'Utilisation Commerciale - Pas de Modification 4.0 International.